HyperFedX:具有防止搭便車機制的可解釋聯邦學習框架
12月 15, 2023·
 ·
3 分鐘閱讀
·
3 分鐘閱讀
張席睿 Rex
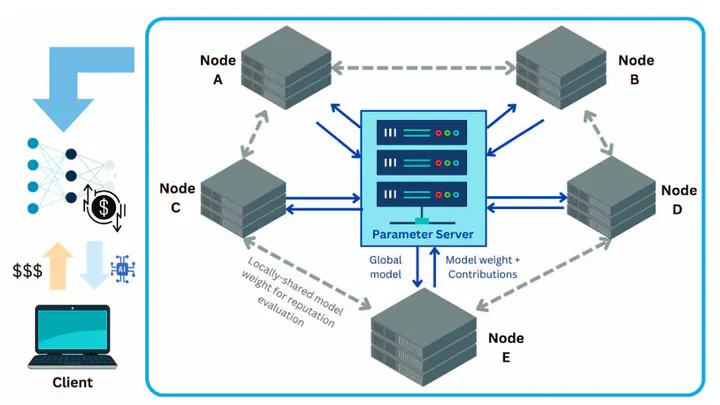 HyperFedX 框架
HyperFedX 框架
摘要
我們開發了 HyperFedX,一個結合超網絡和梯度解釋器的框架,用於檢測和防止聯邦學習中的搭便車行為,同時提供決策透明度。搭便車者通常上傳隨機權重以從全局模型中獲益而不貢獻,降低系統效率和公平性。我們的方法使用 SHAP 值動態分配聚合權重並計算基於聲譽的激勵,創建更具韌性的分散式學習系統。
類型
核心發現
我們開發了 HyperFedX,這是一個利用超網絡和梯度解釋器檢測聯邦學習系統中搭便車行為的框架,在提高分散式模型訓練可靠性的同時提供決策透明度。
為什麼重要
這項研究解決了聯邦學習系統中的關鍵弱點。 搭便車者通過貢獻隨機或未經訓練的權重,同時從全局模型中獲益,破壞了協作學習機制。HyperFedX 不僅檢測這些參與者,還建立了透明的評估機制,維護系統完整性和公平性。
關鍵創新
- 超網絡架構:動態權重分配系統根據貢獻質量調整影響力
- 梯度解釋器整合:提供參與者貢獻評估過程的透明度
- 基於聲譽的激勵機制:通過 SHAP 值計算,獎勵真正的貢獻者
- 自適應聚合:參數服務器優化模型更新,提高系統韌性
我的貢獻
- 設計基於超網絡的自適應聚合算法
- 實現理論模型的代碼
- 開發用於搭便車檢測的效用基礎決策模型
- 將梯度解釋器與超網絡整合,實現透明評估
- 創建基於 SHAP 值的激勵計算框架
深入探討
技術方法
我們的框架使用三個關鍵數學模型來解決搭便車行為的檢測和防止:
1. 基於效用的決策模型
$$U_i = P_i(Contribute) \times R_i(Contribute) - C_i(Contribute) - P_i(Free\text{-}Ride) \times P_i(Detection) \times F_i$$此模型描述了參與節點的決策過程:
- $U_i$ 代表節點獲得的效用(收益)
- $P_i(Contribute)$ 是節點 i 選擇貢獻的概率
- $R_i(Contribute)$ 是貢獻的獎勵
- $C_i(Contribute)$ 是貢獻的成本(計算資源等)
- $P_i(Free\text{-}Ride)$ 是選擇搭便車的概率
- $P_i(Detection)$ 是被檢測為搭便車者的概率
- $F_i$ 是被檢測的懲罰
這個公式使我們能夠模擬節點何時會理性選擇搭便車而非誠實貢獻。當 $U_i > 0$ 時節點會選擇貢獻,當 $U_i < 0$ 時會選擇搭便車。
2. 激勵計算系統
$$I_i = \frac{[\alpha \cdot Contribute_i + \beta \cdot Repute_i]}{\alpha + \beta} \times Profit$$其中:
- $I_i$ 是分配給參與者 i 的激勵
- $Contribute_i$ 根據以下公式測量當前貢獻的質量: $$Contribute_i = \frac{(\sum_{j=1}^{C} dist_{i,j} \times SHAP_{i,j}) \times (\sum_{j=1}^{C} acc_{i,j} \times SHAP_{i,j+C})}{C}$$
- $Repute_i$ 代表從先前輪次累積的聲譽: $$Repute_i = \frac{(\sum_{j=1}^{C} r \times SHAP_{i,j+2C})}{C}$$
- $\alpha$ 和 $\beta$ 是平衡即時貢獻與歷史聲譽的權重參數
- $Profit$ 是可分配的總獎勵
該系統使用 SHAP 值來量化每個參與者在準確度和與全局模型距離方面的貢獻重要性,創建透明的激勵機制。
3. 參數服務器優化
$$\min_{\theta,I_i,\forall i} L(\theta) \cdot [(-\sum_{i=1}^{E} U_i(I_i, \theta_i))/E]$$參數服務器的目標函數:
- 最小化模型損失函數 $L(\theta)$,同時
- 最大化所有參與者的平均效用 $U_i$
- $\theta$ 代表模型參數
- $I_i$ 代表分配給每個參與者的激勵
- $E$ 是參與者總數
這個雙重目標確保全局模型保持高性能,同時創造鼓勵誠實參與的條件。
實現架構
HyperFedX 框架實現包含幾個關鍵組件:
-
超網絡組件:我們實現的超網絡接收四個關鍵輸入:
- 衡量參與者模型與其他模型距離的指標
- 每個參與者模型在驗證數據上的準確度指標
- 來自先前輪次的聲譽分數
- 當前模型參數
-
梯度解釋器整合:我們應用 SHAP 值解釋超網絡的決策:
- 在多個參考點計算梯度
- 使用 K-means 根據重要性對梯度進行聚類
- 選擇最具信息性的梯度來解釋模型決策
-
模擬環境:我們針對以下情況測試了框架:
- 各種搭便車情境(隨機權重、複製權重等)
- 不同的網絡拓撲和參與者行為
- 多種通信模式和激勵結構
研究關聯
此研究連接到以下領域的前沿研究:
- 邊緣計算的聯邦學習框架
- 分散式系統中的可解釋人工智慧應用
- 資源受限環境下的邊緣大型語言模型解決方案
致謝
此研究在陽明交大智慧邊緣與霧運算聯盟實驗室進行,在黃經堯教授的指導下完成,並得到 Sirapop Nuannimnoi 和團隊成員的幫助。